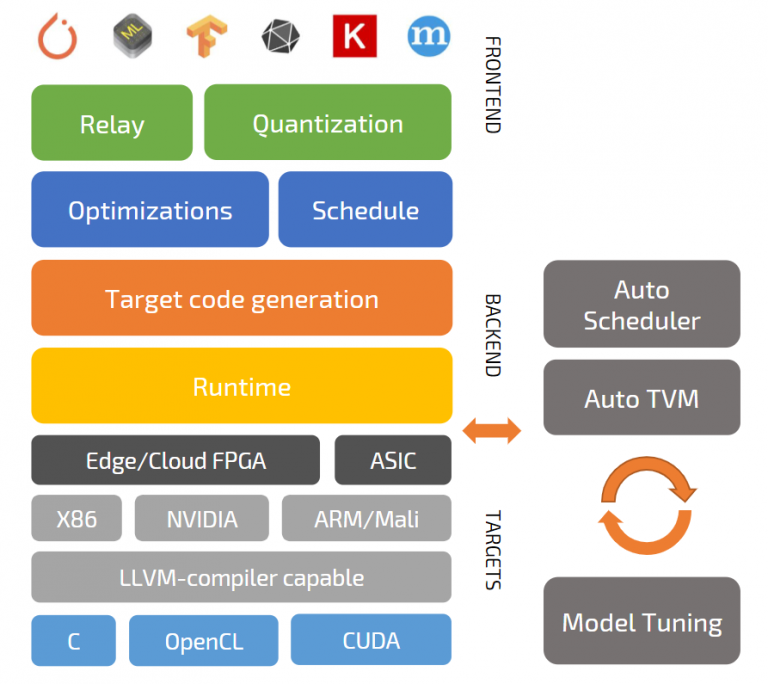
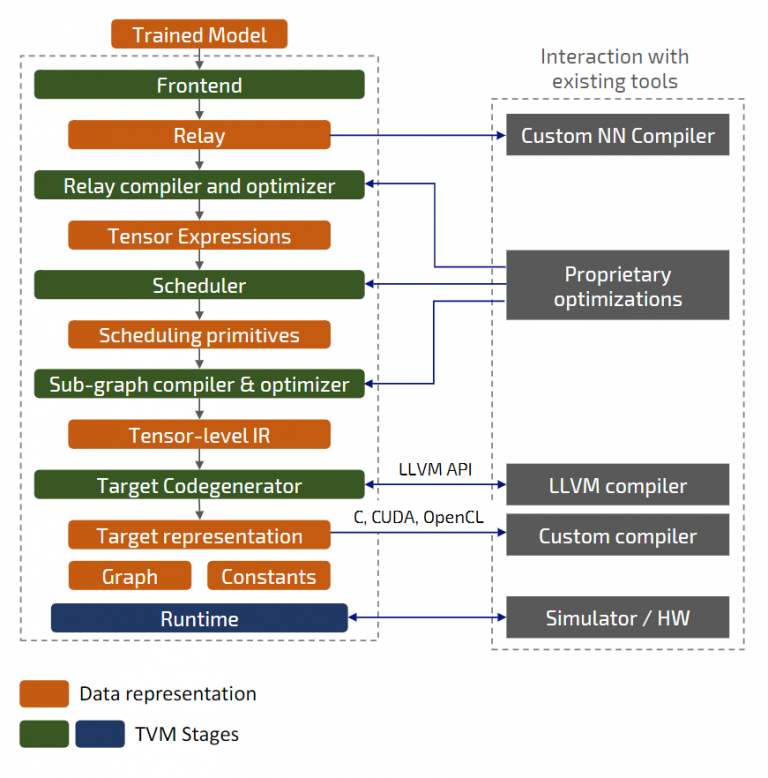
BYOC
- Relay-level backend
- Replace operations or layers with compound device functions
- Special runtime to process intrinsics
LLVM
- Leverage existing LLVM target
- Direct use of LLVM through API
- Compile to LLVM IR, Bitcode, .so
Source
- Generates source code to use with external compiler
- Already supported: C, CUDA, METAL, OpenCL, Vivado HLS